AI 时代的数据革命: 阿里云 DLF 全模态湖仓管理平台的进化与实践
导读AI 智能体时代的数据挑战随着云计算、大数据技术的成熟,以及近年来 AI 大模型和智能体(Agent)的飞速发展,数据已经成为企业最核心的资产。然而,传统的数据架构正面临着前所未有的挑战:
数据模态的爆炸性增长: 数据不再局限于结构化的表格数据,大量的图片、视频、音频、文档等非结构化数据涌入,如何统一高效地管理这些全模态数据成为首要难题。
实时性要求的极致提升: 业务对数据新鲜度的要求从 T+1(天级别)升级到分钟级,现在更需要迈向秒级,以支撑高价值、高风险的实时业务。
架构复杂与成本高昂: 为了兼顾实时与离线,企业常采用复杂的 Lambda 架构,导致开发和运维成本居高不下,且数据一致性难以保证。
作为国内领先的云计算服务商,阿里云深刻洞察这一趋势,持续升级其核心产品——DLF(Data Lake Formation),旨在构建面向未来的全模态湖仓管理平台,为客户提供更简单、更开放、更实时、更安全的统一数据基础。
本文将回顾数据架构的演变,分析 AI 时代对数据平台提出的新要求,并详细解读阿里云 DLF 平台如何从 1.0、2.0 升级至 3.0,最终实现全模态数据统一管理和极致实时响应的技术突破。

主要内容包括以下几个部分:
1. 需求驱动的架构演进:从 Hadoop 到湖仓一体(Lakehouse)
2. AI 时代的新挑战与新要求:Lakehouse 需要再进化
3. 阿里云 DLF 平台的进化之路(1.0 到 3.0)
4. DLF 3.0 全模态湖仓管理平台的架构与核心能力
5. 应用场景与 DLF 带来的价值
6. 结语:面向 AI 未来的统一数据基石
分享嘉宾|李鲁兵 阿里云 智能集团计算平台事业部DLF产品负责人
内容校对|郭慧敏
出品社区|DataFun
01
需求驱动的架构演进:从 Hadoop 到湖仓一体(Lakehouse)
1. 传统数据架构的局限
回顾大数据平台的发展,我们可以看到一个不断追求效率、统一和低成本的过程。
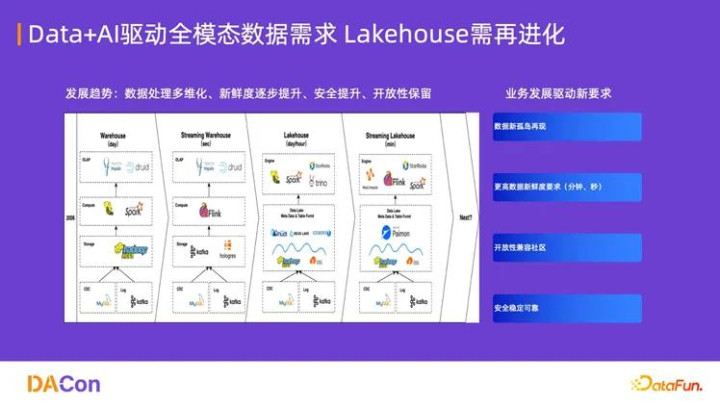
Hadoop 时代(计算与存储耦合): 早期的 Hadoop 集群解决了海量数据存储和批处理问题,但计算与存储紧密耦合,数据新鲜度仅为 T+1 离线处理,架构复杂,组件繁多,运维难度大。
实时数仓的出现(Streaming Warehouse): 针对实时性要求,以 Flink 等为代表的实时计算引擎兴起,配合 Kafka 等消息队列,构建了实时数仓,实现了数据的秒级处理。
Lambda 架构的困境: 实时和离线两套架构并存,形成了 Lambda 架构。它虽然解决了时效性问题,但带来了三大灾难性挑战:
开发运维成本翻倍: 维护两套技术栈和数据链路。
数据一致性难题: 离线和实时两套数据的结果经常不一致。
计算资源浪费: 实时架构通常成本较高。
2. 湖仓一体(Lakehouse)的诞生
为了解决 Lambda 架构的弊端,行业开始探索湖仓一体(Lakehouse)架构。Lakehouse 旨在融合数据湖(低成本、存储灵活)和数据仓库(高性能、结构化管理)的优点,其核心特征是计算与存储分离,并实现流批统一(Stream & Batch Unified)。
阿里云 Stream Lakehouse(湖流一体): 阿里云在此基础上率先提出了“湖流一体”概念,利用诸如 Apache Paimon 等高性能湖存储格式,在统一的平台上实现了数据的分钟级别新鲜度。这在不显著增加成本的前提下,将数据时效性提升了数十倍,满足了绝大多数企业的准实时分析需求。
然而,AI 时代的到来,要求数据平台必须在 Lakehouse 的基础上,进行更深层次的进化。
02
AI 时代的新挑战与新要求:Lakehouse 需要再进化
AI 大模型和智能体对数据平台提出了更高、更复杂的要求,推动着数据架构必须突破现有的“分钟级”和“结构化”限制。
1. 挑战一:数据新鲜度从分钟级到秒级
在金融风控、实时推荐、安全监控等高风险、高价值的业务场景中,分钟级的延迟已经不可接受,要求数据必须达到秒级甚至毫秒级新鲜度。下一代湖仓平台必须能够以近乎流计算的实时性,在湖存储上完成数据的摄取和处理。
2. 挑战二:全模态数据的统一管理与 AI 赋能
智能体和 AI 大模型的训练与推理,需要平台能高效地处理和检索 结构化(表格)、半结构化(JSON)和非结构化(图片、视频、文本) 等各种模态的数据。
传统痛点:结构化数据和非结构化数据通常分开管理,形成新的“数据孤岛”。例如,检索特定场景下的图片,需要耗时耗力。
AI 时代的需求:要求平台能将结构化标签(如时间、地点)与非结构化内容(如图片、视频)关联起来,实现全模态混合检索。例如,通过 SQL 查询结合向量化技术,先用结构化条件过滤海量数据,再用向量搜索进行高效召回,极大地提升了 AI 数据准备的效率。
3. 业务发展驱动的四大新要求
综合来看,AI 驱动下的下一代数据平台必须具备以下四大核心能力:
全模态统一管理:消除结构化与非结构化数据的新孤岛。
极致数据新鲜度:从分钟级跃升至秒级。
开放性兼容社区:保持技术开放,兼容主流湖存储格式,避免厂商锁定(Vendor Lock-in)。
企业级安全可靠:安全和稳定性是平台运行的基石。
03
阿里云 DLF 平台的进化之路(1.0 到 3.0)
阿里云 DLF(Data Lake Formation)作为湖仓管理的核心引擎,其发展历程精准地反映了数据架构的趋势。

1. DLF 1.0:云原生元数据服务
DLF 1.0 阶段主要定位为云原生元数据服务,核心价值是兼容 Hive Meta Store(HMS) 协议。这解决了用户将本地 Hadoop 集群迁移至云端时,元数据管理不兼容的问题,为存算分离架构提供了稳定的元数据层。
2. DLF 2.0:开放湖仓与流批一体的分钟级实时
面对 Lakehouse 架构的流行,DLF 2.0 进行了重大升级,解决了传统 HMS 的局限性(如高并发写冲突、非结构化数据管理不足)。
开放架构:采用业界主流的 Rest Catalog 机制,提升性能和开放性。
流批统一:基于 Apache Paimon 等湖存储格式,利用其高效的 Upsert/Partial Update 和 Change Log 能力,实现流式消费,构建了真正的流批一体平台。
核心价值:以低成本实现了数据的分钟级实时化,淘汰了复杂的 Lambda 架构。
3. DLF 3.0:全模态与秒级实时突破
为迎接 AI 时代的挑战,DLF 再次升级,进入 3.0 阶段,正式定位为全模态数据湖仓管理平台。
DLF 3.0 的使命是补齐两大核心能力:
全模态数据管理:统一纳管所有数据类型,支持 AI 和 BI 双场景。
向秒级新鲜度过渡:实现极致的实时性。
DLF 3.0 平台的一体化设计体现在:统一数据管理层,但计算引擎层保持开放灵活,兼容阿里云自研和社区主流引擎。
04
DLF 3.0 全模态湖仓管理平台的架构与核心能力
DLF 3.0 采用清晰的分层架构,以“一横一纵”的平台能力,支撑全模态和极致实时性目标。
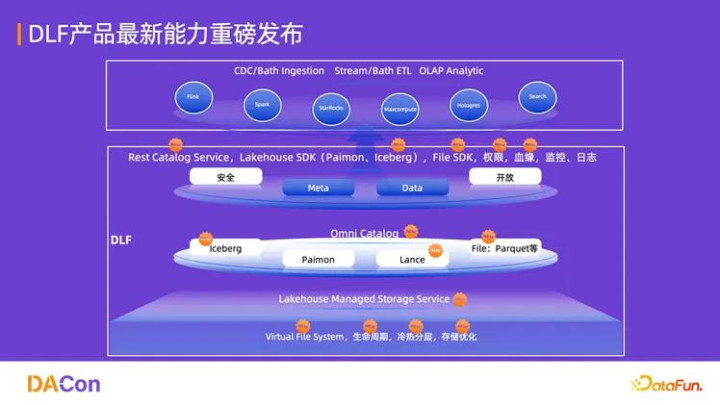
DLF 3.0 企业级服务覆盖了从数据入湖到全管理。

1. 核心层:Omni Catalog 与统一存储服务
(1)统一开放目录(Omni Catalog)
Omni Catalog 是 DLF 的“大脑”,实现了对所有数据资产的统一纳管。
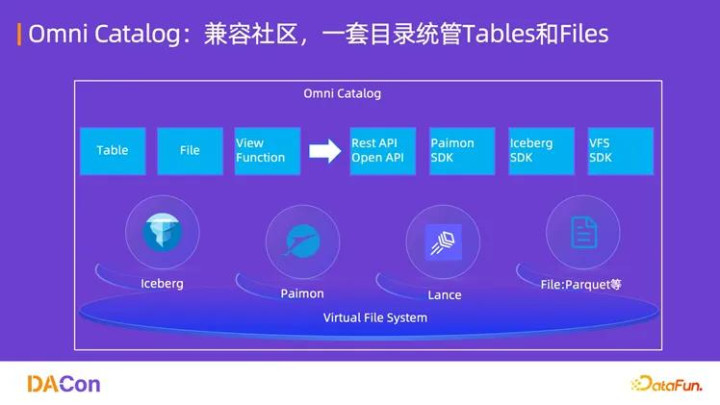
多湖格式支持:不仅支持表格(Table)的元数据管理,还支持 Paimon、Iceberg 等主流湖格式,以及面向向量化和全模态存储的 Lance 格式。
开放接口:提供 Rest API 和 Open API,以及针对不同湖格式的 SDK,确保了平台的开放性和易用性。
双范式支持:通过统一的 Table 和 File 接口,同时支持面向 BI(商业智能)的 SQL 分析和面向 AI(人工智能) 的非结构化数据处理。
(2)湖仓托管存储服务(Lakehouse Managed Storage Service)
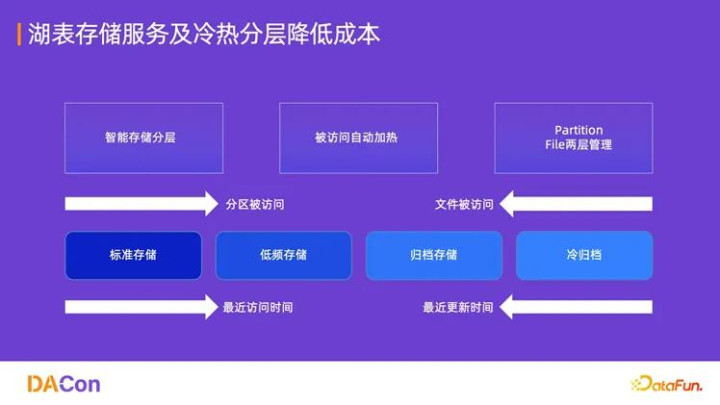
该服务是 DLF 的“数据底座”,构建在阿里云 OSS(对象存储服务)之上,提供企业级的存储优化能力,实现降本增效。
智能冷热分层:根据数据的访问频率和更新时间,自动将数据在标准存储、低频存储、归档存储和冷归档之间进行迁移。被访问的冷数据可实现自动加热,确保性能,同时大幅节省存储成本(可达 30% 以上)。
虚拟文件系统(VFS):屏蔽底层存储差异,提供统一的文件访问接口。
生命周期管理:自动进行数据分区和快照清理,简化运维。
2. 数据链路层:数据入湖与湖表管理优化
(1)数据入湖(Data Ingestion):零代码 ETL
DLF 致力于实现 Zero ETL(零代码 ETL),简化数据摄取复杂度。
实时入湖(CDC):利用 Flink CDC 等技术,实时捕获数据库变更事件(Binlog),支持 Schema 的自动演进,实现秒级数据入湖。
批量入湖:通过 DataWorks 数据集成和 Serverless Spark 等工具,支持多源数据的离线批量迁移。
全模态入湖:重点支持视频、音频、文件等非结构化数据高效入湖,为 AI 场景提供数据基础。
存量系统迁移:提供产品化的迁移工具,支持 Hive、Hudi、Iceberg 等存量系统快速平滑迁移到 DLF 平台,并提供数据校验机制,保证迁移准确性。

(2)湖表管理与优化
为提升读写性能和降低成本,DLF 提供智能化的湖表优化服务:
智能 Compaction(小文件合并):自动扫描并合并湖存储中的小文件,提升查询效率。
自动分桶(Auto Rescale):用户只需指定分桶键,平台可根据数据量的变化,自适应调整分桶策略,以保证查询时的并发最优性能。
快照管理:基于策略管理数据快照的生命周期,并自动清理孤立文件(orphan files),确保存储空间的有效利用。
3. 安全与权限:企业级保障
安全是数据平台的生命线。DLF 在安全方面提供企业级保障:
细粒度权限控制:支持对 Catalog、Database、Table、Column 等不同粒度设置细粒度权限。
跨引擎协同授权:利用阿里云 RAM 体系,实现一次授权、跨引擎公用,简化了权限管理,避免重复授权的风险。
完善的审计和治理:全面记录操作日志,支持安全治理审计,满足各类合规要求。
4. 性能与成本效率全面提升
DLF 平台通过一系列技术优化,显著提升了数据平台的效率和经济性:
元数据性能:元数据查询性能可提升 10 倍以上。
存储成本:智能冷热分层和存储优化,可节省存储成本 30% 以上。
查询加速:配合计算引擎协同加速,查询性能可提升 50%。

05
应用场景与 DLF 带来的价值
阿里云 DLF 全模态湖仓管理平台通过架构简化和能力升级,为客户带来了显著的业务价值,主要体现在架构效率、AI 赋能和成本效益三个方面。
1. 湖流一体:极致实时与架构简化
DLF 的湖流一体架构,将数据新鲜度推进到秒级,同时彻底替换了复杂的 Lambda 架构。

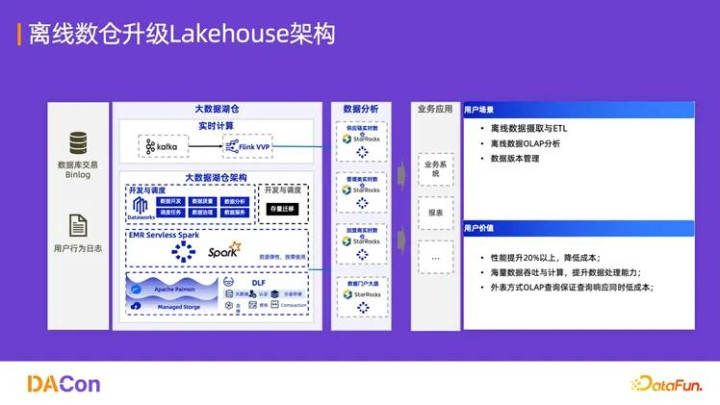
2. 离线数仓升级 Lakehouse 架构
架构简化:统一流批处理,降低了开发和运维的复杂度。
时效性提升:以接近离线数仓的成本,实现了秒级的实时数据能力。
开放计算生态:DLF 作为统一管理层,支持 Flink、Spark、StarRocks、Hologres、MaxCompute 等多计算引擎接入,灵活应对各种分析和处理需求。
3. 全模态数据管理与高效检索
DLF 通过 Omni Catalog 和统一存储服务,实现了结构化与非结构化数据的统一管理和高效处理。
统一存储与管理:将各种模态数据统一存储和管理,消除数据孤岛,降低了跨表和文件管理的复杂度。
AI 赋能高效检索:支持全模态混合检索。例如,用户可以通过 SQL 语句,结合结构化标签和 向量化(Vectorization) 技术,实现“在特定天气、特定地点的场景下,查找特定颜色车辆图片”的高效圈选。这极大地加速了 AI 模型训练前的数据准备过程。

4. 实战案例:助力淘宝闪购业务准时上线,实现全链路实时运营
在 2025 年秋季,阿里云 DLF 3.0 成功支撑了阿里巴巴集团闪购业务的准时上线。该业务对数据实时性要求极高,需在秒级内完成用户行为分析、库存预警与营销决策。因为在去年阿里巴巴集团就做了 Alake 项目,基于 Lakehouse 架构构建了整个平台,所以基于 DLF 可以让流批做更好地融合。面向用户场景会有 BI 场景、AI 场景,这套架构可以很好地兼容两种场景的使用,灵活选择多种引擎应对业务方的需求。

06
结语:面向 AI 未来的统一数据基石
AI 智能体的快速发展,正在颠覆传统的数据处理范式。企业对数据平台的期盼,已经从简单的“能存、能算”升级到“能实时、能全模态、能开放、能赋能 AI”。
阿里云 DLF 全模态湖仓管理平台正是为了应对这一时代挑战而生。它以安全开放为基石,以 Omni Catalog 为核心,通过湖仓托管存储服务实现降本增效,最终以秒级新鲜度和全模态管理能力,构建了一个面向未来的统一数据基础。
DLF 的持续进化,不仅是技术的升级,更是帮助企业实现数据资产价值最大化的关键基础设施。在 AI 驱动的浪潮下,阿里云 DLF 正助力客户以前所未有的速度和效率,挖掘全模态数据的巨大潜力。
以上就是本次分享的内容,谢谢大家。